What's in the RedPajama-Data-1T LLM training set
By A Mystery Man Writer
Description
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, …

Denys Linkov on LinkedIn: Together.ai releases a new LLM dataset

Catching up on the weird world of LLMs

Catching up on the weird world of LLMs

LLaMA clone: RedPajama – first open-source decentralized AI with

Training data used to train LLM models

Fine-Tuning Insights: Lessons from Experimenting with RedPajama

Meet Skill-it: A Data-Driven Skills Framework for Understanding

RedPajama replicates LLaMA dataset to build open source, state-of

How Decontaminated Rephrased Datasets made “LLAMA 13B” to defeat

Machine Learning – Page 6 – Data Machina Newsletter – a deep dive

Open-Sourced Training Datasets for Large Language Models (LLMs)
Web LLM runs the vicuna-7b Large Language Model entirely in your
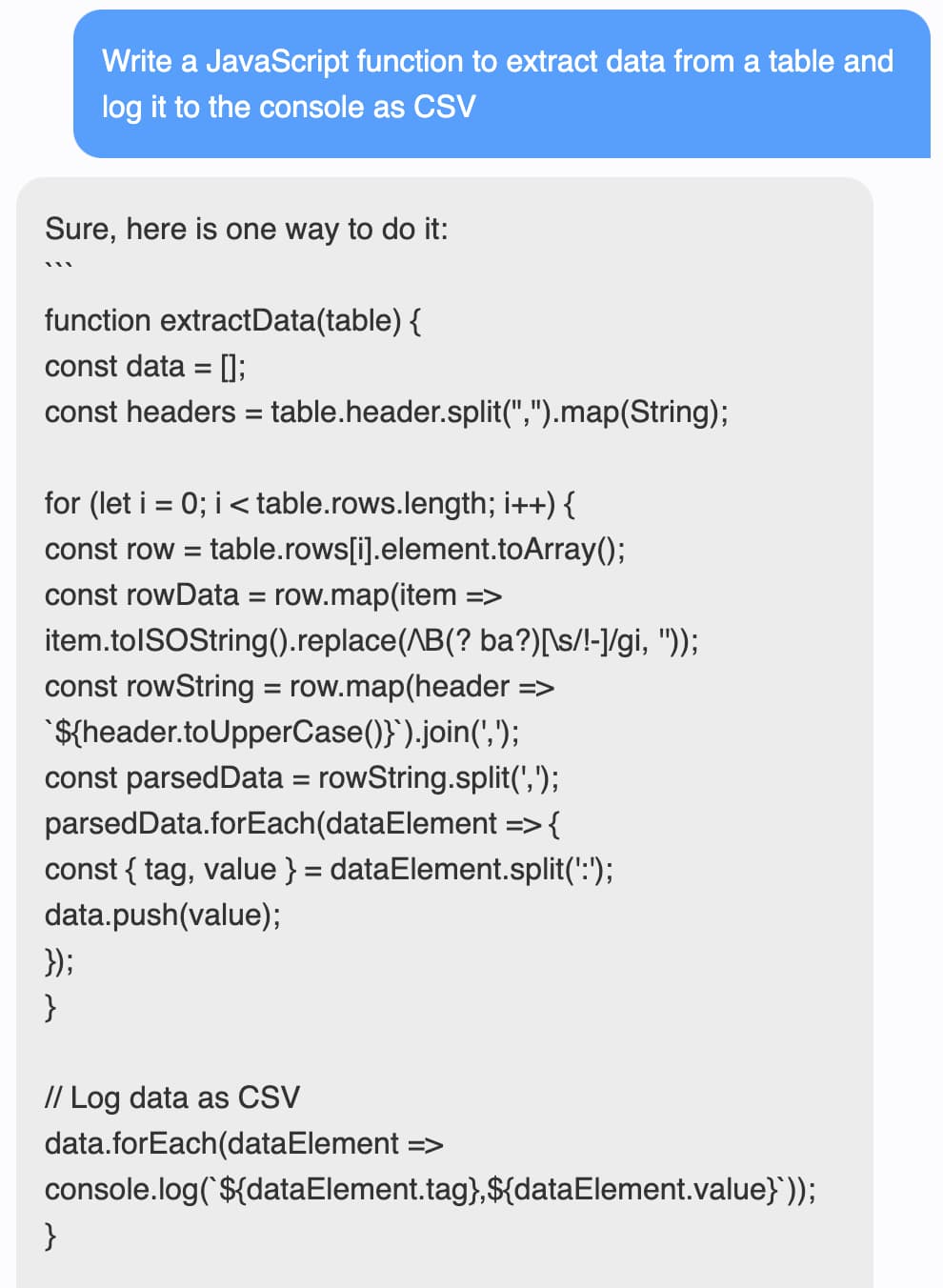
RedPajama Project: An Open-Source Initiative to Democratizing LLMs
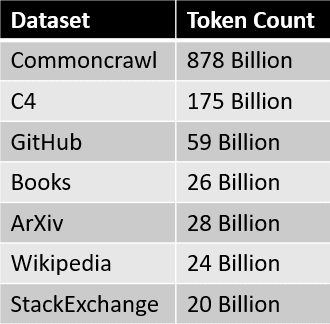
Standard LLMs are not enough. How to make them work for your business
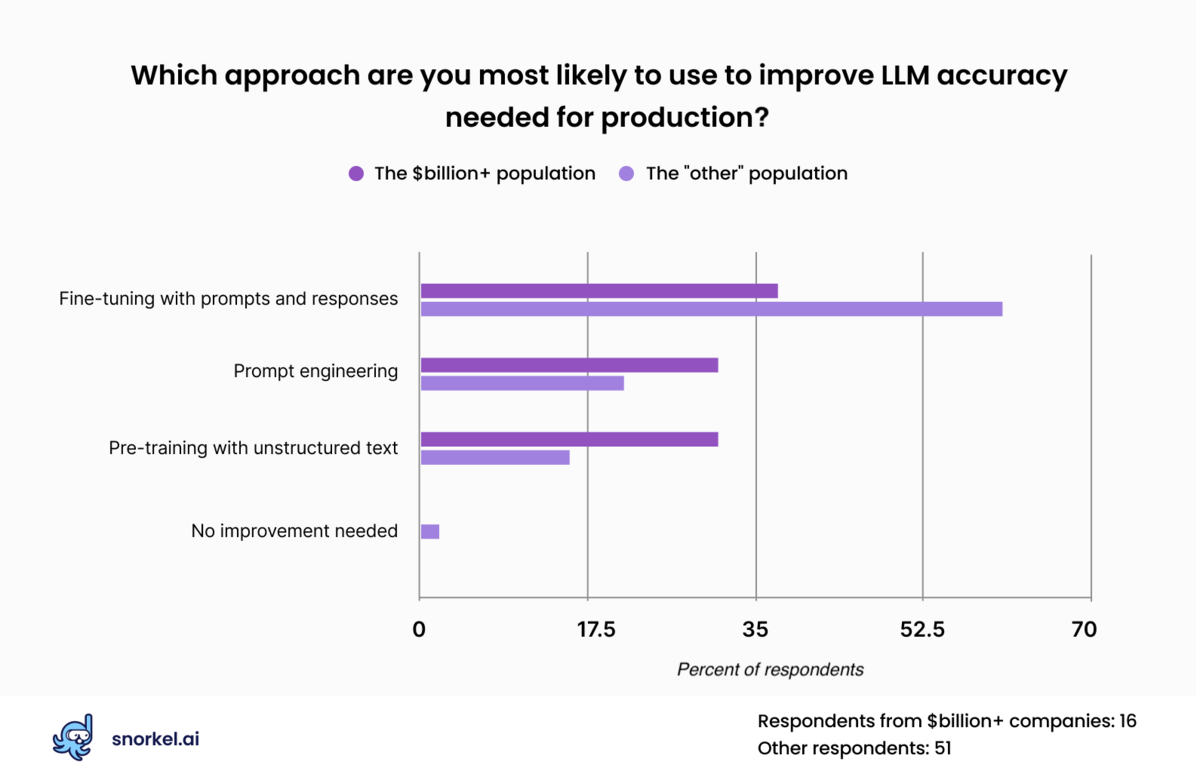
Supervised Fine-tuning: customizing LLMs
from
per adult (price varies by group size)







