BERT-Large: Prune Once for DistilBERT Inference Performance
By A Mystery Man Writer
Description
Compress BERT-Large with pruning & quantization to create a version that maintains accuracy while beating baseline DistilBERT performance & compression metrics.

NeurIPS 2023

Dipankar Das posted on LinkedIn

Distillation of BERT-Like Models: The Theory
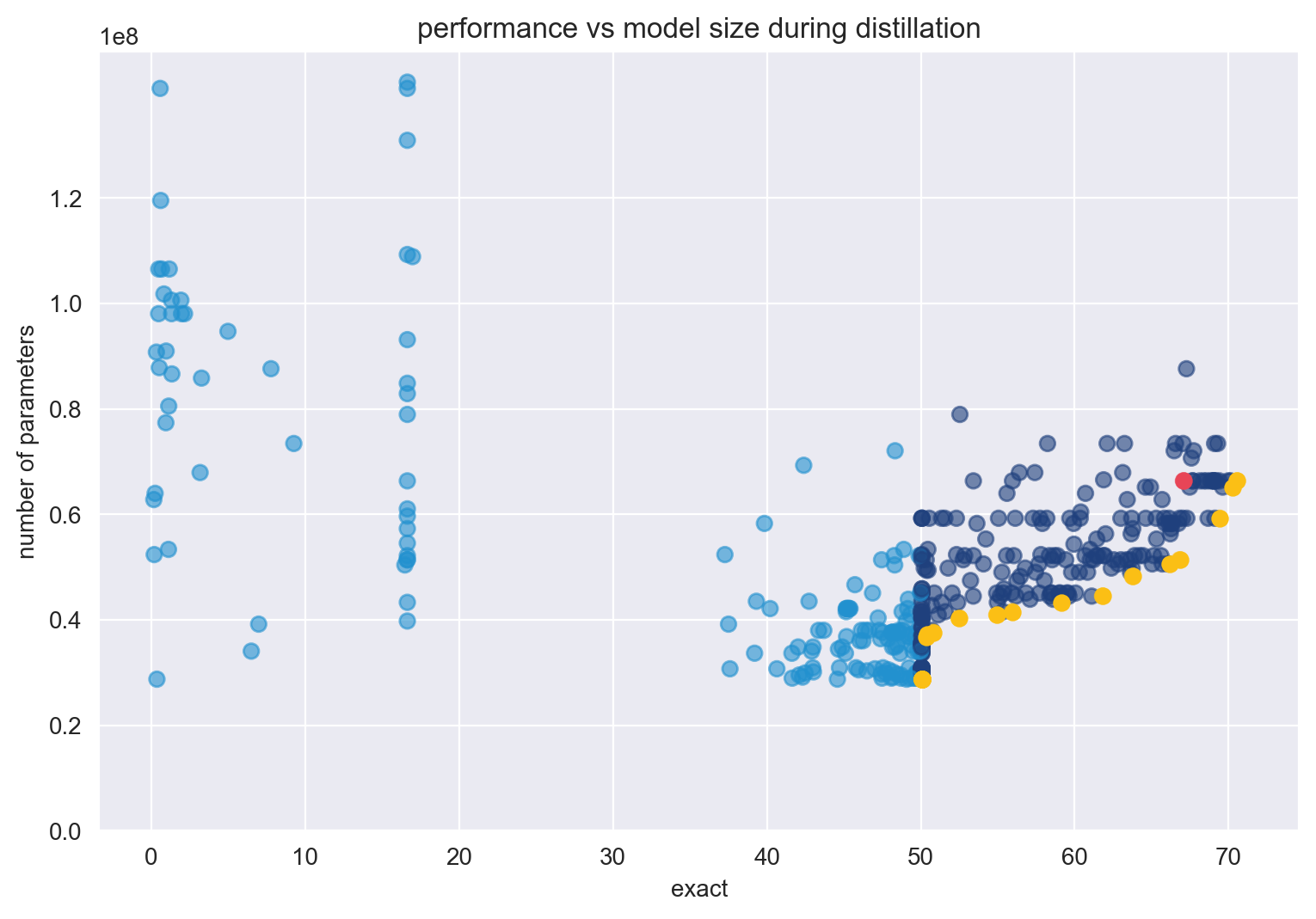
Efficient BERT: Finding Your Optimal Model with Multimetric Bayesian Optimization, Part 1

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

Distillation of BERT-Like Models: The Theory

Large Language Models: DistilBERT — Smaller, Faster, Cheaper and Lighter, by Vyacheslav Efimov

Poor Man's BERT - Exploring layer pruning

PDF] Prune Once for All: Sparse Pre-Trained Language Models
from
per adult (price varies by group size)






